
异步爬取17K小说网站
免责声明
声明: 本教程仅供学习交流使用,请遵守相关法律法规和网站使用条款。
为了防止给该网站的服务器带来过大压力,造成不可挽回的结果。本篇教程的并发数,和间隔时间设置很保守,同时只爬取一本小说作为学习。
成果展示
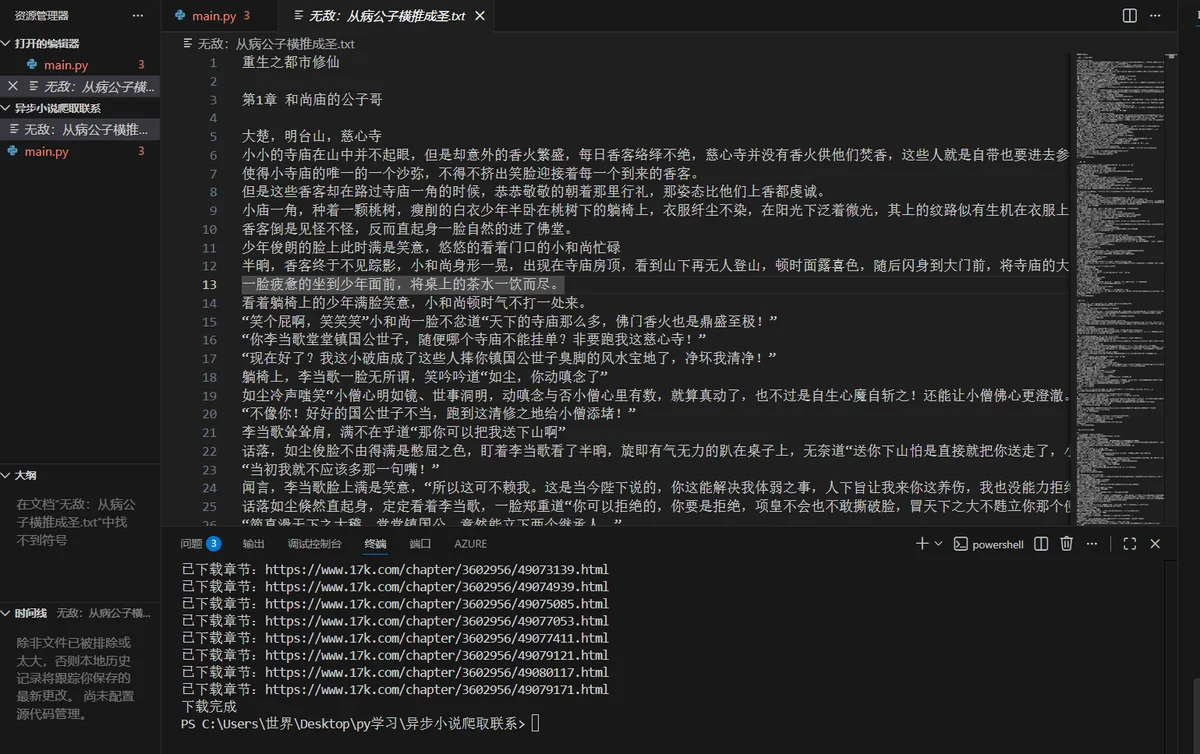
爬取网站17小说网
爬虫目标与思路
目标
- 完整获取: 下载指定小说的所有章节内容
- 高效执行: 利用异步编程提升下载速度
- 便于阅读: 要通过数据清洗是下载下来的小说易易于阅读
思路
- 爬取目录页获取该小说所有章节的url地址列表
- 使用异步爬虫爬取该小说的所有章节
- 将数据保存到txt文件中
网页分析
- 打开控制台

发现控制台有调试暂停看不到源码
- 取消断点,刷新看是否会有源码出现
源码出现了,寻找章节url是在源码中还是通过数据包动态加载的
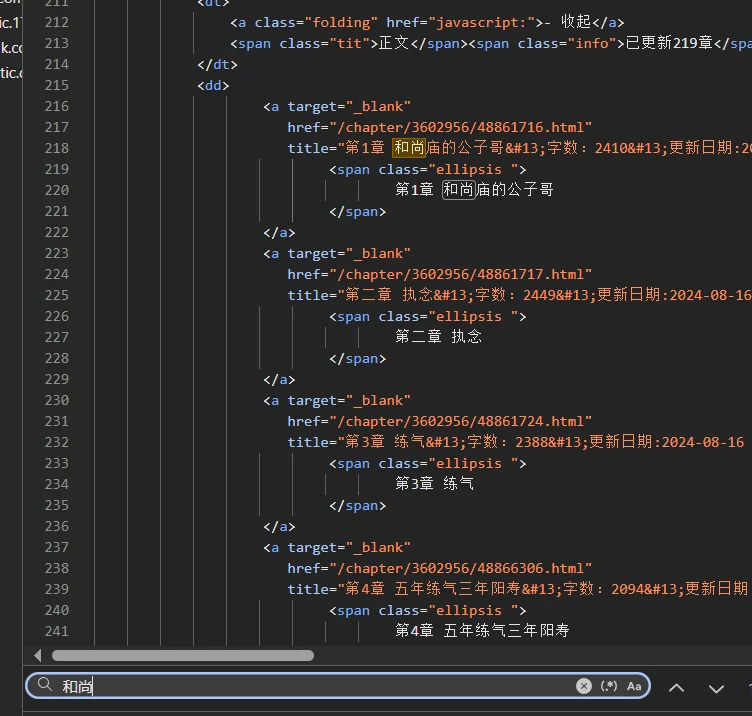
- 搜索确定章节url位置
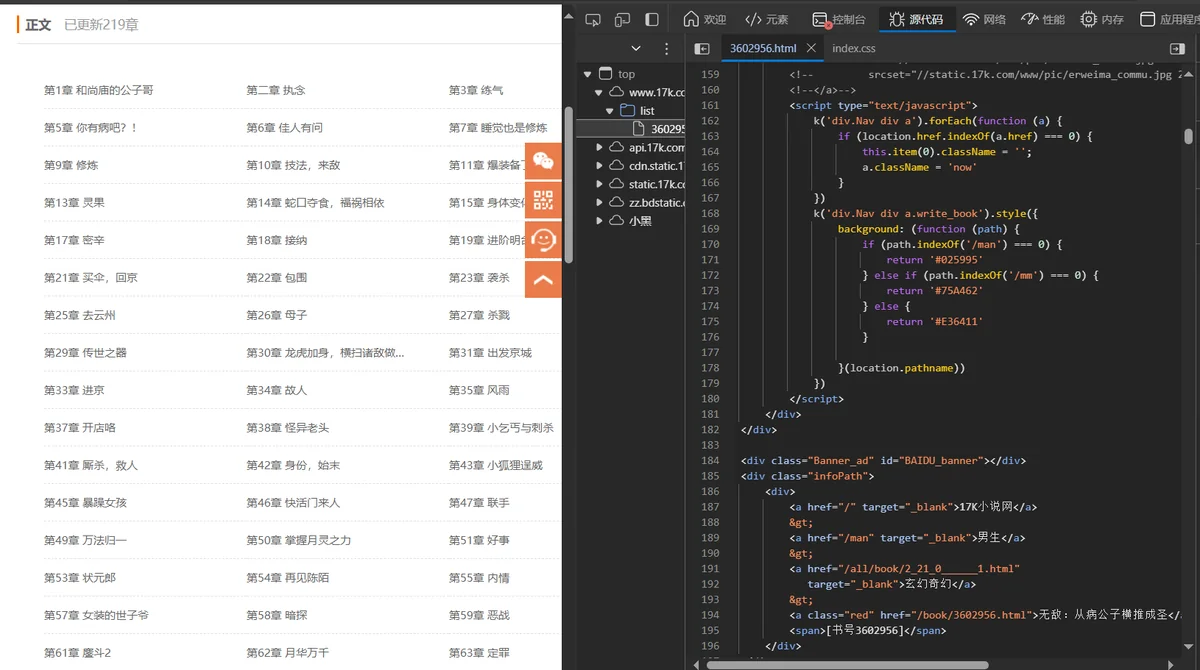
发现所需要的url链接在源码之中,分析确定其位置在
tree.xpath('//dl[@class="Volume"]/dd/a/@href') - 观察每一章中文本在什么位置
随便打开一章分析其源码发现
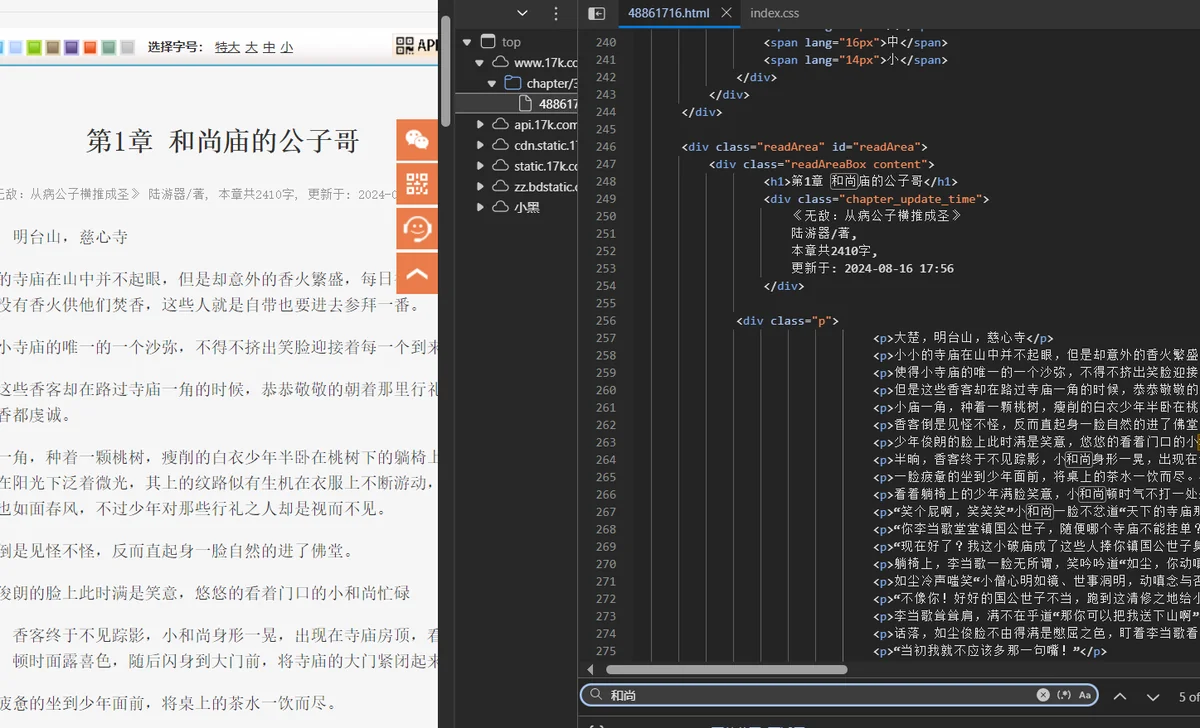
发现文本内容也在页面源码中,位置是
title = tree.xpath('//div[@class="readAreaBox content"]/h1/text()')[0] cont = tree.xpath('//div[@class="readAreaBox content"]/div[@class="p"]/p/text()')


通过playright过阿里云waf验证
WAF验证确定
如果是一般网站就可以爬取了,但是17K这个小说网站有WAF反爬验证,简单来说就是你第一次访问网站的时候,网站不会直接返回给你网页内容,而是一串网页执行代码,你的浏览器读懂这些,再运行写入cookie(一把钥匙),带着cookie再次访问才能访问到你需要的内容。
可以通过观察网络请求确定

发现有两个一样的对网址请求,分别点开
- WAF验证
- 真实我们需要的网页
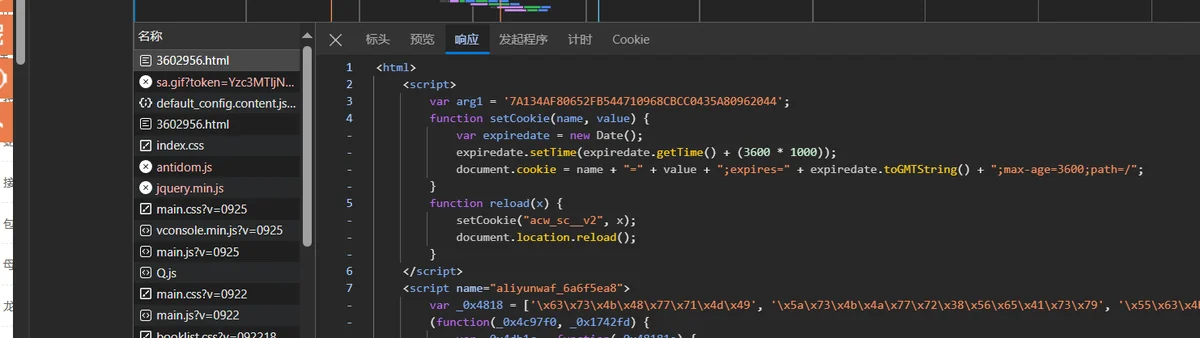
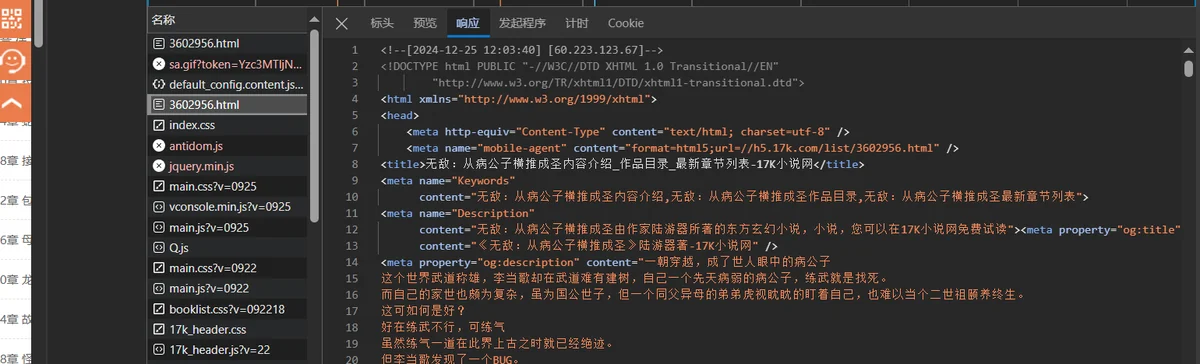
可以清楚的看见一个是看不懂的乱码,一个是具有我们需要信息的源码
通过WAF验证的方法
单纯的使用httpx,是通过不了验证的,用逆向得到cookie的算法,之后python模拟,过于复杂,时间成本太高。我比较常用的方法是首先使用playright(一个无头浏览器)去访问该网站,获取cookie,之后用httpx带着这个cookie去访问网站,这样就可以抓取数据了。
这种Playwright + HTTPX混合方案巧妙结合了两者的优点,形成了高效且稳健的爬虫架构:
1. 绕过复杂验证,降低技术门槛
Playwright作为无头浏览器,能够模拟真实用户访问网站,自动执行JavaScript、处理动态渲染和登录验证,轻松获取有效的登录态Cookie。这避免了手动逆向分析Cookie生成算法的复杂过程,大大降低了技术实现难度和时间成本。
2. 兼顾稳定性与高效率
- 稳定性保障:Playwright获取的是真实浏览器生成的Cookie,与正常用户完全一致,有效规避了反爬机制检测
- 效率提升:后续使用轻量级的HTTPX进行异步并发请求,避免了浏览器渲染的开销,实现了数十倍的速度提升
3. 资源利用最优化
仅在初始阶段使用一次Playwright(约2-3秒),后续成千上万的章节请求均由HTTPX处理。这种设计既保证了Cookie的有效性,又避免了持续运行浏览器的巨大资源消耗(内存减少90%以上)。
4. 架构灵活性高
这种分层设计易于扩展和维护:
- 可随时调整并发数、请求间隔等参数
- 若网站验证机制升级,只需调整Playwright部分
- 支持多种存储格式和后续处理
实现代码
async def get_cookies():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
context = await browser.new_context()
page = await context.new_page()
await page.goto(url)
await page.wait_for_load_state("networkidle")
cookies = await context.cookies()#获取cookie
await browser.close()
cookie_dict = {c["name"]: c["value"] for c in cookies}
return cookie_dict代码实现
过完WAF验证,也确定了我要抓取的内容位于网站什么位置,剩下的就很简单了,就是用python请求服务器,之后获取数据,保存数据。本文就不赘述了,直接放出源码以供学习。
所用的库
| 库名 | 主要作用 |
|---|---|
| playwright | 模拟浏览器行为,获取登录态Cookie |
| asyncio | 异步编程框架,实现并发请求控制 |
| httpx | 异步HTTP客户端,高效发起网络请求 |
| lxml | HTML解析库,提取网页中的结构化数据 |
| random | 生成随机延迟,避免被反爬机制检测 |
源码
from playwright.async_api import async_playwright
import asyncio
import httpx
from lxml import etree
import random
url = "https://www.17k.com/list/3602956.html"
###---------###
#playwright获取cookie
###---------###
async def get_cookies():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
context = await browser.new_context()
page = await context.new_page()
await page.goto(url)
await page.wait_for_load_state("networkidle")
cookies = await context.cookies()#获取cookie
await browser.close()
cookie_dict = {c["name"]: c["value"] for c in cookies}
return cookie_dict
###---------###
#使用httpx异步请求页面
###---------###
async def fetch_page(url: str, cookies: dict) -> str:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0"
}
async with httpx.AsyncClient(cookies=cookies, headers=headers, timeout=20) as client:
response = await client.get(url)
response.raise_for_status()
return response.text
# 解析HTML获取章节链接
def get_chapter_links(html: str)->list:
tree = etree.HTML(html)
return tree.xpath('//dl[@class="Volume"]/dd/a/@href')
#获取单章节内容
async def fetch_one_chapter(url: str, client: httpx.AsyncClient, semaphore: asyncio.Semaphore) -> str:
async with semaphore:
for i in range(3): # 重试3次
try:
response = await client.get(url)
response.raise_for_status()
print(f"已下载章节:{url}")
break # 成功则跳出重试循环
except httpx.HTTPError as e:
if i == 2: # 最后一次重试失败,抛出异常
raise e
await asyncio.sleep(2) # 等待2秒后重试
sleep_time = 0.7+random.random()*1.3#随机休眠0.7-2秒
await asyncio.sleep(sleep_time)
return response.text
#获取多章节内容
async def fetch_multiple_chapters(urls: list, cookies: dict,max_concurrent: int) -> list:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0"
}
semaphore = asyncio.Semaphore(max_concurrent)
async with httpx.AsyncClient(cookies=cookies, headers=headers, timeout=20) as client:
tasks = []
for url in urls:
all_url = f"https://www.17k.com{url}"
tasks.append(fetch_one_chapter(all_url, client, semaphore))
return await asyncio.gather(*tasks)
#解析章节
def parse_chapter(html: str) -> str:
tree = etree.HTML(html)
title = tree.xpath('//div[@class="readAreaBox content"]/h1/text()')[0]
cont = tree.xpath('//div[@class="readAreaBox content"]/div[@class="p"]/p/text()')
content = "n".join(cont)
full_text = f"{title}nn{content}nn"
return full_text
if __name__ == "__main__":
cookie = asyncio.run(get_cookies())
links_page = asyncio.run(fetch_page(url, cookie))#获取章节列表页面
chapter_links = get_chapter_links(links_page)#解析章节链接
print("章节链接获取完成,共计:", len(chapter_links))
#chapter_links = [
# "/chapter/3602956/48861716.html",
# "/chapter/3602956/48861717.html"
#]
for link in chapter_links:
print(link)
print("正在下载中")
taxts = asyncio.run(fetch_multiple_chapters(chapter_links, cookie, 2))#获取章节内容
book_title = "无敌:从病公子横推成圣"
all_content = f"{book_title}nn"
for text in taxts:
content = parse_chapter(text)
all_content += content
with open(f"{book_title}.txt", "w", encoding="utf-8") as f:
f.write(all_content)
print("下载完成")总结
17k这个网站爬取的主要难点就是WAF验证,其他的就没有什么反爬措施了,但是不能一次性不加限制的爬取很多章节,不然容易405被封IP。




