本文最后更新于100 天前,其中的信息可能已经过时,如有错误请发送邮件到963470751@qq.com
小红书爬虫项目总结
📋 项目概述
之前一直对小红书的爬取望而却步,因为小红书有json加密,而我完全不会逆向,但是偶然间发现DrissionPage这种无头浏览器,完全不需要了解逆向,就简单尝试了一下。该文章仅是一次简单的尝试,记录爬取的思路和期间遇到的问题和解决方法
🛠 技术栈
| 组件 | 用途 |
|---|---|
| Python 3.8+ | 主要编程语言 |
| DrissionPage | 核心爬虫库,融合浏览器自动化与请求监听 |
| Chromium | 无头浏览器,用于渲染动态页面 |
| JSON解析 | 处理API返回的结构化数据 |
| XPath/CSS Selector | 定位和提取页面元素 |
🔄 核心工作流程
flowchart LR
A[启动无头浏览器] --> B[监听数据接口]
B --> C[模拟搜索操作]
C --> D[智能滚动加载]
D --> E[批量捕获数据包]
E --> F{是否还有新数据?}
F -- 是 --> D
F -- 否 --> G[解析并存储数据]
G --> H[结束任务]🧩 实现过程
明确目标
小红书可以爬取的内容有很多,我希望可以获取小红书某一类内容下比较热门的帖子的点赞等数据
分析网站
- *思考方法**:观察小红书发现可以用搜索按钮获取某一类的的帖子,并且热度都还可以。如果先搜索我需要的类目,即可进入我需要的帖子的信息流页面。同时小红书网页的数据是动态不断加载出来的,理论上如果我访问搜索我想要爬取类目的网站,并且监听含有标题和跳转链接的包,之后再解析js数据,即可跳转访问不同帖子,再从不同帖子的页面获取点赞等数据即可完成目标
flowchart TD
A[开始: 启动浏览器与监听器] --> B[模拟搜索目标类目]
B --> C{进入信息流/搜索结果页}
C --> D[向下滚动页面<br>触发动态加载]
D --> E[监听并捕获数据包<br>(含标题、ID、跳转链接)]
E --> F{是否停止滚动?}
F -- 否,继续加载 --> D
F -- 是,开始处理 --> G[解析数据包<br>得到初始帖子列表]
G --> H[初始化任务队列]
subgraph Phase2[第二阶段:详情页抓取]
H --> I{队列是否为空?}
I -- 否 --> J[从队列取一个帖子]
J --> K[访问该帖子详情页]
K --> L[监听并捕获详情页数据包]
L --> M[解析JSON<br>提取点赞、收藏等完整数据]
M --> N[存储/整合该帖子完整数据]
N --> I
end
I -- 是 --> O[结束任务<br>输出数据集]- 控制台分析:
- 找到自己所需要监听的包在控制台网络搜索一篇笔记的标题,查看那些包含有
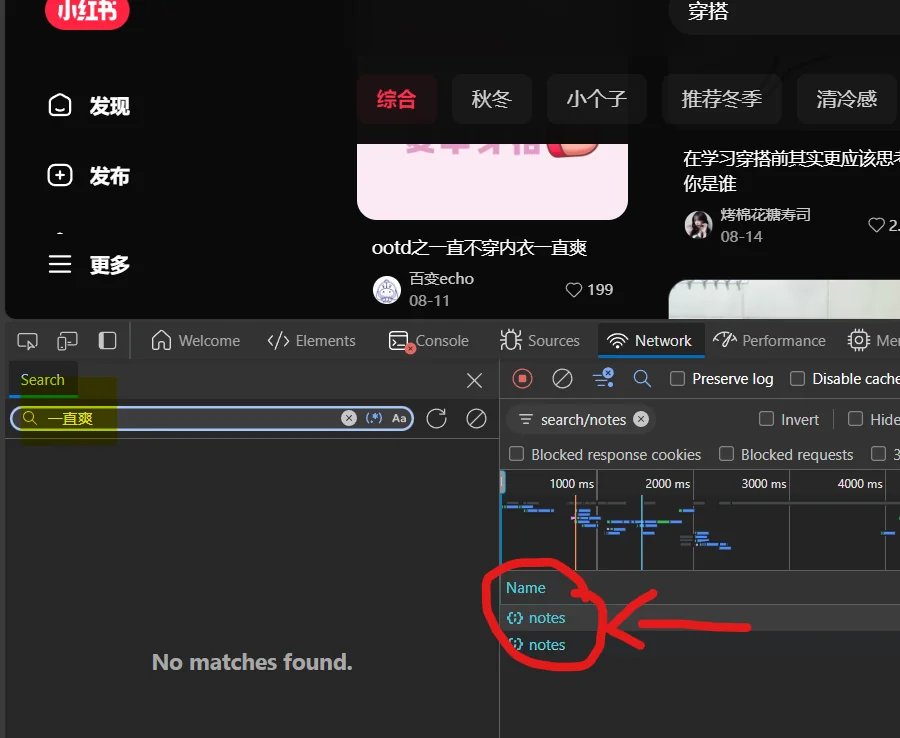
发现notes这个包中含有文章标题
- 打开包看看含有什么内容
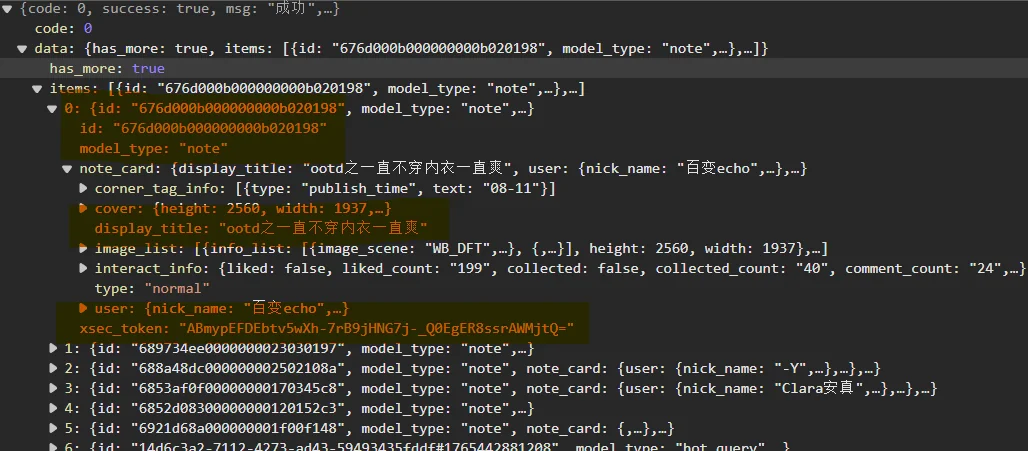
发现具有22条帖子的内容,并且观察到其中的id和和xsec_token是访问具体帖子url所携带的
url可以写成
return f"https://www.xiaohongshu.com/explore/{self.id}?xsec_token={self.xsec_token}&xsec_source=pc_search"同时note_card中含有文章的标题,作者,还有分享,点赞,评论数等内容,因此我们无需进行二级爬取内容即可获取我们需要的数据
-
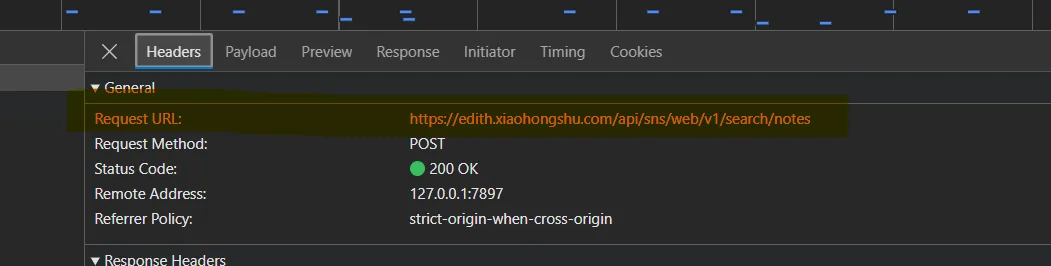
数据监听
查看标题观察其url

确定监听“search/notes”
代码实现
-
创建容器保存采集内容
class note: title: str="" #标题 xsec_token: str="" #xsec_token, id: str="" collected_count: int=0 #收藏 comment_count: int=0 #评论 like_count: int=0 #点赞 share_count: int=0 #分享 type: str="" #类型 @property def url(self) -> str: return f"https://www.xiaohongshu.com/explore/{self.id}?xsec_token={self.xsec_token}&xsec_source=pc_search" -
创建浏览器并且监听所需要的包
keyword = "穿搭" # 需要搜索的关键字 url = f"https://www.xiaohongshu.com/search_result?keyword={keyword}&source=unknown" tab = Chromium().latest_tab tab.listen.start("search/notes") tab.get(url) -
进行滚动循环并且依次解析和保存包中的数据
for i in range(3): # 模拟下拉加载更多 pack = tab.listen.wait() js = pack.response.body print(f"正在爬取第 {i+1} 页...") for item in js.get("data", {}).get("items", []): note0 = item n = note() n.title = note0.get("note_card", {}).get("display_title", "") n.id = note0.get("id", "") n.xsec_token = note0.get("xsec_token", "") interact = note0.get("note_card", {}).get("interact_info", {}) n.comment_count = interact.get("comment_count", 0) n.collected_count = interact.get("collected_count", 0) n.like_count = interact.get("liked_count", 0) n.share_count = interact.get("shared_count", 0) notes.append(n) tab.scroll(1500) sleep(3) -
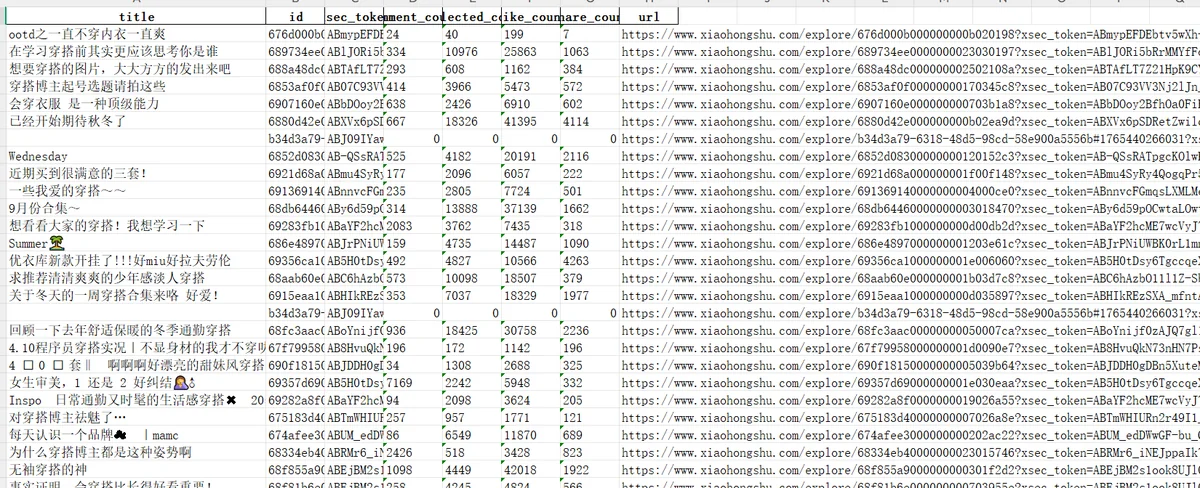
保存所需的数据到excle
# 将爬取到的 notes 保存为 Excel 文件 output_file = "xhs_notes.xlsx" save_notes_to_excel(notes, output_file) print(f"已保存 {len(notes)} 条记录到 {output_file}"
📝 总结和不足
本项目成功实现了对小红书搜索结果的自动化爬取,攻克了动态网页渲染、接口数据监听、反爬机制应对等关键技术难点。通过本次实践,不仅掌握了DrissionPage等现代爬虫工具的使用,更深入理解了动态网站的数据加载机制和爬虫工程化的核心要点。
核心收获:
- 动态网站爬取的关键在于找到数据接口,而非解析页面HTML
- 模拟人类操作模式是规避反爬的有效策略
- 良好的数据模型设计是保证项目可维护性的基础
- 爬虫项目需要平衡数据获取需求与对目标网站的尊重
此项目可作为学习动态网页爬虫技术的典型案例,相关技术和思路也可迁移至其他类似平台的爬取任务中。
可以改进的地方
-
爬取的时候会误怕小红书的夹在正常帖子中间的搜索帖子,需要后期数据清洗一下
-
小红书网页目前最多直接爬取200多条数据,之后就服务器就不提供数据了(但是也够用了)
-
没有在前面添加筛选的操作,比如选择类型,发布时间等,不过也够用了